
AI Agents in Production (Part 4): Evaluating AI Agents
MLOps.WTF Edition #26
Ahoy there 🚢,
This episode is brought to you by Oscar Wong, MLOps Engineer at Fuzzy Labs.
In the last piece, James argued that predictive power doesn’t come with guarantees. Benchmarks don’t prove your system is safe in production, and “it worked in testing” isn’t evidence that it will behave under real-world pressure.
This article is next in our agents in production series and continues that argument, but at, as you might have guessed, the agent level.
When a model becomes an agent, it stops being just a predictor and starts taking actions. It retrieves data, selects tools, and decides what to do next. At that point, you’re not just judging the answer. You’re judging what it did to get there.
And that’s where this piece begins…
The £2.3 Million Email
Picture this: A financial services firm deploys an AI agent to handle customer queries about their investment portfolios. The agent can look up account data, calculate returns, and explain complex financial products. You did your homework. You picked the best model based on the benchmarks, tested for hallucination rates, checked faithfulness scoring, measured semantic similarity and BLEU scores, and verified instruction following. Everything looked solid.
Three weeks into production, a customer asks about their pension transfer options. The agent retrieves the correct regulatory information, reasons through the customer’s situation, identifies the right form to recommend... and then confidently provides a link to a document that was deprecated eighteen months ago. The customer follows the outdated process, misses a critical deadline, and loses their protected transfer rights.
The agent didn’t hallucinate. Every step of its reasoning was sound. It retrieved real data from a real database. The problem? Nobody was evaluating whether the agent’s tool usage was returning current information. The retrieval worked perfectly. It just retrieved the wrong thing.
This is why evaluating agents requires something fundamentally different from evaluating a simple LLM.

Why Agents Break Differently
A standalone LLM takes an input and produces an output. If it’s wrong, you can trace the problem to the model itself: bad training data, poor prompting, or the inherent stochasticity that James covered in his piece on why evaluation matters.
Agents are different. They don’t just generate text. They think, decide, and act. A typical agent might:
Interpret a user’s intent
Plan a sequence of steps to address it
Select and invoke external tools (databases, APIs, calculators)
Reason over the results
Decide whether to continue or respond
Generate a final answer
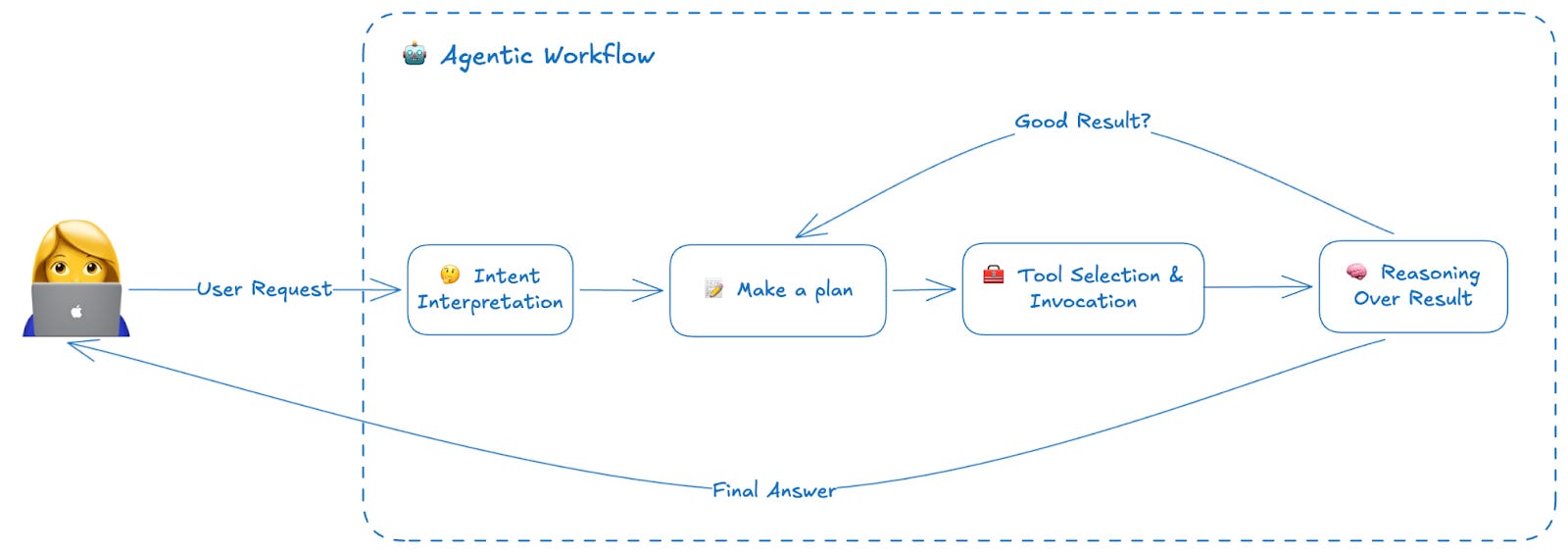
Each of these steps can fail independently, and failures compound. An agent that misinterprets intent will select the wrong tools. An agent that selects the right tools but invokes them incorrectly will reason over garbage data. An agent that does everything right but takes fifteen steps instead of three will burn through your API budget and frustrate your users with latency, even if it eventually lands on the right answer.
This is why multi-step decision systems demand multi-layered evaluation. You can’t just check whether the final answer is correct; you need visibility into every layer of the agent’s operation.
The Four Dimensions of Agent Evaluation
After digging through academic surveys (arXiv’s comprehensive benchmark review, a study of 20+ production agent teams), industry frameworks (LXT, Maxim, Weights & Biases), and tools that the Fuzzy Labs teams actually use, I’ve synthesised what “multi-layered evaluation” actually means in practice. It breaks down into four dimensions, each targeting a different point where agents can fail.
1. Quality and Correctness: “Is the output right?”
This is the most obvious one, but for agents it’s trickier than it sounds. You’re not just checking whether an answer is factually correct. You’re evaluating whether the agent completed the user’s actual task.
Key metrics:
Task completion rate: Did the agent achieve what the user wanted?
Answer accuracy: Is the final response factually correct?
Faithfulness: Does the response accurately reflect the retrieved information?
Hallucination rate: Did the agent make things up?
For RAG-based agents (those that retrieve information from documents or databases), faithfulness could become especially critical. An agent might produce a plausible-sounding answer that completely misrepresents what the source documents actually say.
2. Reasoning and Planning: “Did the agent ‘think’ correctly?”
Even when an agent produces a correct final answer, it might have gotten there through flawed reasoning, or through an unnecessarily convoluted path. This matters because flawed reasoning that happens to work once will fail unpredictably later.
Key metrics:
Reasoning path validity: Does each step logically follow from the previous one?
Tool selection accuracy: Did the agent choose the right tools for the task?
Step efficiency: Did it take a reasonable number of steps, or did it flail?
Recovery behaviour: When something went wrong, did it adapt sensibly?
This is where trajectory evaluation comes in, examining not just where the agent ended up, but the path it took to get there.
3. Tool and Integration: “Did it use tools correctly?”
Agents interact with the world through tools: APIs, databases, search engines, calculators. Each tool interaction is a potential point of failure that has nothing to do with the LLM’s language capabilities, and everything to do with integration.
Key metrics:
Tool invocation success rate: Did the API calls/MCP server calls actually work?
Parameter accuracy: Did the agent pass correct arguments to tools?
Result interpretation: Did it correctly understand what the tool returned?
Integration reliability: Are external dependencies stable?
Remember our pension transfer example? The tool invocation was successful and the database returned data, but the agent didn’t validate whether that data was current. This dimension catches those failures.
4. Operational: “Does it work in production?”
An agent that produces perfect answers but takes thirty seconds to respond, or costs £5 per query, isn’t going to survive in production. Operational metrics keep agents economically and practically viable.
Key metrics:
Latency: End-to-end response time, plus time-to-first-token for streaming
Throughput: How many requests can you handle concurrently?
Cost per task: Token usage, API calls, compute resources
Error rates and recovery: How often does it fail, and does it fail gracefully?
These metrics often reveal surprising trade-offs. A more capable model might produce better answers but cost ten times as much per query. An agent that double-checks its work might be more accurate but twice as slow.
When and How: The Three Modes of Evaluation
Knowing what to measure is only half the battle. The other half is knowing when and how to measure it. In practice, agent evaluation happens across three distinct modes:
Offline Evaluation: Testing Before You Ship
No surprises here, just like any traditional ML application. This is your safety net before deployment. You build test datasets, either from real historical interactions or synthetically generated, and run your agent against them in a controlled environment.
The goal is to catch obvious failures before users do. Does the agent handle edge cases? Does a prompt change break something that used to work? Does a new model version maintain quality?
The challenge is that offline evaluation can only test what you anticipate. Users will always find ways to break your agent that you never imagined.
Online Monitoring: Watching Production
Once your agent is live, you need continuous visibility into how it’s actually performing. This means tracing every request, logging every tool call, and tracking metrics in real time.
Online monitoring catches the failures that offline testing misses. Take our financial services example: you might not have anticipated how users actually talk in the real world, with heavy use of acronyms and jargon (”What’s my ISA allowance for the current FY?” or “Can I transfer my SIPP to a SSAS?”). Beyond catching edge cases, online monitoring helps you understand both user and agent behaviour in context: the weird phrasing that confuses intent detection, the slow API that causes timeouts at scale, the gradual drift in quality as the world changes around your static agent.
A recurring theme from teams running agents in production is to focus on what users actually experience, not just what the model outputs. A study of 20+ production agent teams found that practitioners care more about whether the agent solved the user’s problem than traditional software metrics like uptime. Maxim’s evaluation framework puts it simply: session-level success (did the whole interaction work?) matters more than individual response quality.
LLM-as-Judge: Using AI to Evaluate AI
Some aspects of agent quality are genuinely difficult to evaluate programmatically. Is this response helpful? Is it appropriately cautious? Does it match the desired tone?
This is a newer technique that’s gained traction as LLMs have become more capable. The idea is to use a (typically larger, more capable) language model to evaluate your agent’s outputs against defined criteria. You provide rubrics (explicit scoring guidelines) and the judge model assesses each response.
This approach is powerful but requires calibration. Judge models have their own biases. They can be gamed. They’re not a replacement for human evaluation, but they scale in ways that human review cannot.
[Watch Evidently’s video from the MLOps.WTF meet up on this]
Tools to Help You Evaluate
The agent evaluation ecosystem has evolved rapidly, largely because teams quickly learned the hard way that shipping agents without proper evaluation is a recipe for disaster. There are dozens if not hundreds of tools out there now, but here are some of the ones we use at Fuzzy Labs, organised by what they help you evaluate:
For RAG and Retrieval Quality: RAGAS
If your agent retrieves information from documents or databases, RAGAS (Retrieval Augmented Generation Assessment) provides purpose-built metrics for RAG pipelines:
Context Precision: How much of the retrieved context is actually relevant?
Context Recall: Did we retrieve everything we needed?
Faithfulness: Does the answer accurately represent the source material?
Answer Relevancy: Does the response actually address the question?
RAGAS is open-source, integrates with most major frameworks, and can generate synthetic test datasets when you don’t have labelled examples. It’s become table stakes for any team building retrieval-based agents.
For Tracing and Debugging: Pydantic Logfire and Opik
When an agent fails, you need to understand where in its execution the failure occurred. This is where observability platforms shine.
Pydantic Logfire (from the team behind Pydantic) is built on OpenTelemetry, giving you standardised tracing across your entire stack. It monitors LLM calls, agent reasoning, API latency, database queries, and vector searches. If you’re already using Pydantic for validation (and let’s be honest, most Python AI projects are), the integration is seamless.
Opik (from Comet) positions itself as an all-in-one platform, covering evaluation, prompt management, and optimisation under one roof. It comes with a built-in dashboard, runs fast, and integrates with CI/CD pipelines out of the box via Pytest.
Both tools support LLM-as-judge evaluations, dataset management, and the kind of session-level analysis that agents require. The choice often comes down to your existing stack and whether you prefer OpenTelemetry standards (Logfire) or a more opinionated evaluation-first approach (Opik). One practical advantage of Opik is its built-in dashboard, whereas self-hosting Logfire’s UI requires an enterprise licence.
For Performance and Load Testing: Locust
Quality metrics mean nothing if your agent can’t handle production traffic. This is where traditional load testing tools enter the picture, though with some adaptations for LLM workloads.
Locust is a Python-based industry standard for simulating concurrent users and measuring system behaviour under load. For LLM agents, you’ll want to track LLM-specific metrics alongside traditional ones:
Time to First Token (TTFT): How long until the user sees something?
Output tokens per second: How fast does the response stream?
Inter-token latency: Is the streaming smooth or choppy?
Some teams also test their tools and integrations directly, bypassing the LLM entirely. This identifies infrastructure bottlenecks without burning through API costs.
From Metrics to Action
Collecting metrics is pointless if you don’t act on them. The final piece of the evaluation puzzle is closing the loop: turning measurements into improvements.
Set meaningful thresholds. What task completion rate is acceptable? What latency is too slow? Define these before you launch, not after something breaks.
Alert on the right signals. Not every metric needs to page someone at 3am. Distinguish between “investigate tomorrow” and “wake up the on-call engineer.” Focus alerts on user-facing impact, not internal metrics.
Automate where possible. Some responses to degradation can be automated: rolling back a prompt change that increased error rates, switching to a faster (if less capable) model during traffic spikes, routing low-confidence queries to human review.
Build feedback loops. The best evaluation systems feed production learnings back into development. Queries that fail in production become test cases. User feedback, both explicit and implicit, shapes future iterations.
The Path Forward
Agent evaluation is still relatively new, and the tools are evolving rapidly. What’s clear is that the old model of “test in staging, pray in production” doesn’t work for systems this complex and this stochastic.
The teams getting this right share a common approach: they evaluate at every layer, they monitor continuously, and they treat evaluation not as a one-time gate but as an ongoing practice. They accept that agents will fail, and they build systems to detect those failures quickly, understand them deeply, and recover gracefully.
James made the case for why evaluation matters. The tools and frameworks now exist to put that into practice. The question is no longer whether to invest in agent evaluation, but how deeply to embed it into your development and operations workflow.
Because eventually, someone’s going to ask your agent about their pension. And you’ll want to know, really know, whether it’s giving them the right answer.
Oscar is an MLOps engineer at Fuzzy labs, and has a passion for both machine learning and snowboarding. He holds a Master's degree in AI from the University of Manchester. When he's not working on his snowboarding tricks, you can find him indulging in some delicious Japanese cuisine.
And finally
What’s coming up
Our next MLOps.WTF meetup is on the 25th of March, themed around Agentic AI in financial services. Tickets are going fast! Make sure you’ve got yours.
🗓️ Wednesday 25th March — Manchester
Our recipe book is served!

Hot off the pass, our first edition cookbook has just been released for download: a collection of practical recipes for building delicious, repeatable AI systems with open source tools.
Each recipe is a working template for a specific AI use case, grounded in solid MLOps foundations. Get your copy 👇
About Fuzzy Labs
We’re Fuzzy Labs, a Manchester-based MLOps consultancy founded in 2019. We’re engineers at heart, and nerds that are passionate about the power of open source.
Want to join the team? We’ve got some open rolls/roles 🥖…
Open roles:
Not subscribed yet? You should be. The button is right here!
The next issue will be a deep dive into agent security, with Matt Squire.
Or equally, why not follow us on LinkedIn to see more BTS bits and pieces, alongside updates around future events and thought pieces 🍅.