
Edge AI: shipping models into the real world
MLOps.WTF Edition #24

Our MLOps.WTF meetup #7, where Arm’s new office proved (1) extremely nice, (2) “labyrinthine”, and (3) capable of producing the most professional safety briefing we’ve ever had.
There’s a point in most ML systems where the cloud stops feeling abstract and starts feeling expensive. Not just in money, but in time. In latency. In the number of things that have to go right before someone can act on an insight.
The MLOps landscape was built around cloud deployment. Elastic compute. Predictable networking. Logs you can reach. Rollbacks that are mostly just a button. In that world, you can afford to park certain questions for later:
How big will my models get
How fast do I need inference to run
What’s my pipeline for getting data back for future training runs?
The edge removes your ability to postpone them.
When the model sits next to the camera, the sensor, the machine, the crop, the doorbell, reality really is knocking at the door.
So the question hanging over MLOps.WTF #7 was simple enough: when does it stop making sense to send everything to the cloud?







Raj (Fotenix):From Cloud to Edge: The Next Phase of Scalable Crop Intelligence
Raj opened by grounding the room in the realities of food production:
In the UK, most fruit is imported, and a large proportion of vegetables too. Fresh produce, especially things like leafy greens, degrades as it moves through long supply chains. Nutritional value drops. Time and temperature matter. Many greenhouses are old. Labour is short. Margins are thin. On a £2.20 bag of apples, growers make about three pence. When intervention is late, it’s lost yield. By the time you’ve “fixed it later”, the opportunity has usually gone.
That’s the environment Fotenix operates in.
They build camera systems for greenhouses that help growers spot plant stress and decide when to intervene. You deploy them quickly and start getting useful signals fast. Today, the setup is cloud-first: images go up, pipelines run, metrics come out.
The problem shows up at scale. Each site generates huge volumes of data. In rural environments, with limited bandwidth, that turns insight into something that arrives too late to act on. As Raj put it, the issue isn’t compute. It’s bandwidth, and more specifically the assumption that every byte needs to travel before it becomes useful.
So they’ve become selective when looking at what to move to the edge and what to keep in the cloud. Some things earn their place close to the data: basic quality checks, pulling out the parts of an image that matter, turning pictures into signals. Other things don’t: training, cross-site analysis, anything that needs global context or doesn’t benefit from immediacy.

Hardware isn’t the limiting factor. The sites already run capable devices. The harder part is operating them. Once you have hundreds of devices in the field, reliability, observability, and fleet management become the real constraints.
Before moving more computation outward, Fotenix is putting effort into the fundamentals. Lightweight runtimes. Local observability. Remote fleet management. The goal is to make sure that when computation does move closer to the data, the system doesn’t become blind or fragile.
Summed up simply: edge is a consequence of maturity. If edge feels risky, that usually means the system isn’t ready yet.
Sam (Fuzzy Labs): Shipping ML to the Edge: A Practical Guide
Sam followed by zooming in on what all of this looks like from an MLOps point of view.
He opened by admitting that speaking into a microphone still makes him feel like he’s on X Factor. Thankfully, instead of “Edge of Glory”, he walked through where edge changes the MLOps lifecycle.
To keep things concrete, he used the tongue-in-cheek”Don’t Ring” doorbell as case study, an anonymised version of a real Fuzzy Labs project. The problem: they had a facial recognition system that worked well, except it failed when people weren’t looking at the camera, or stood too close, or too far away. The solution: build a separate model that detects unusable images and filters them out before they hit the facial recognition system. The model is small and efficient, so it runs it on the device itself without killing the battery.
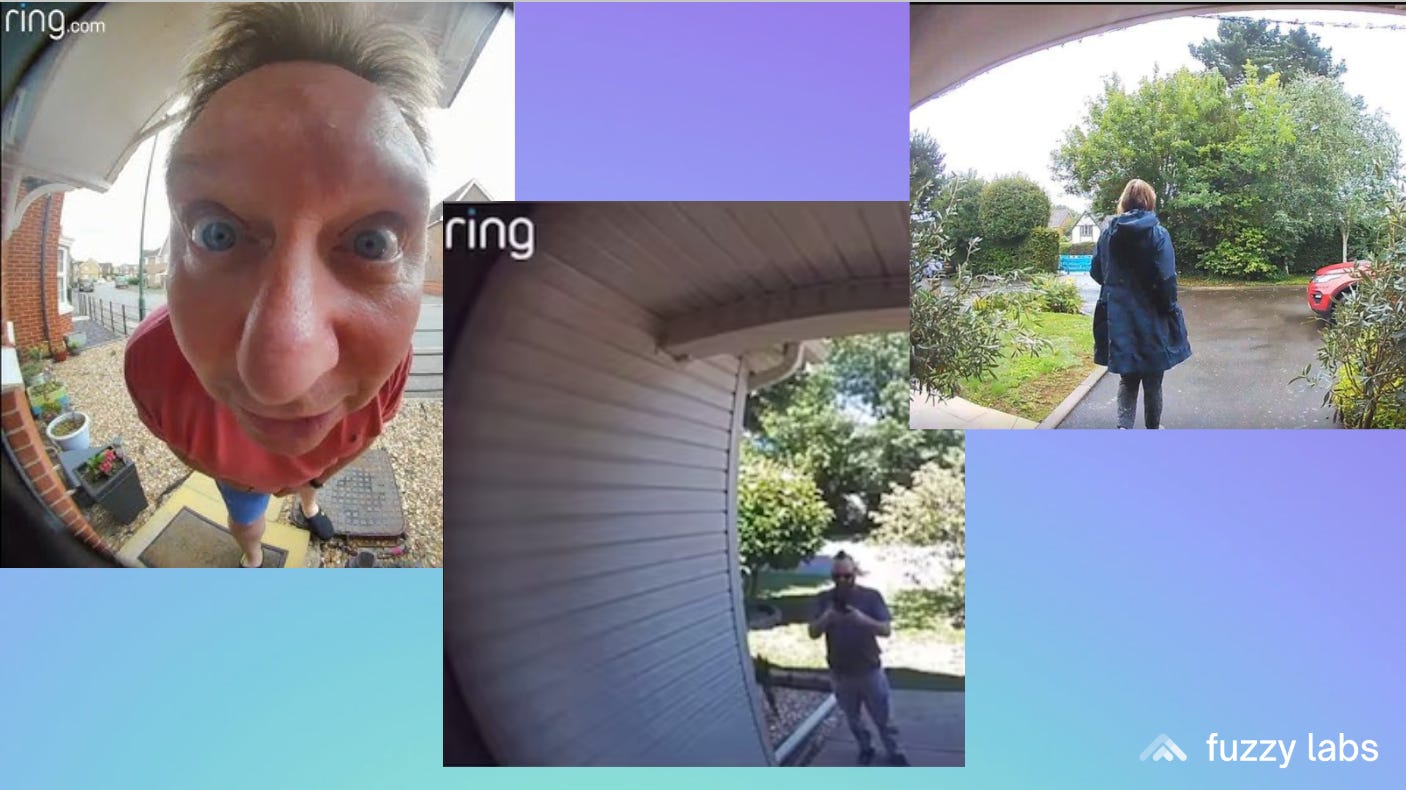
Models need to be small. Power matters. Privacy often means you don’t get access to real data.
In this case, there was no data at all. Open datasets can get you moving. Synthetic data helps too - Gemini generates realistic training images for about two pence each. But Sam was clear about the catch: synthetic data helps you train. It doesn’t tell you whether the model will behave in the real world. If your evaluation data doesn’t match what the device actually sees, you’ll find out later.
Experiment tracking came up next. He put up a slide most people saw themselves in immediately:
“We’ve probably all been there at some point with something like my_model_V3_best_USE_THIS_ONE_final.”
Deploy the wrong model to the cloud and you redeploy. Deploy it to a device you can’t easily reach and you are running around collecting devices or sending apology emails to customers.. Versioning, lineage, knowing what’s running where. Things you can sometimes get away with being loose about in the cloud start to matter much sooner.
Model optimisation followed the same pattern. Every size reduction is a trade-off. You only really understand those trade-offs if you measure performance in the conditions the model will actually run in, not just against training metrics.
Deployment doesn’t get easier either. Different devices, different architectures, different toolchains. Sam mentioned tools like PlatformIO as a way to avoid rebuilding everything from scratch each time.
The problems Sam walked through aren’t new. Data quality, experiment tracking, model optimisation, deployment complexity - they all exist in cloud systems too. What edge removes is the buffer that makes cloud mistakes recoverable. Deploy the wrong model to cloud and you redeploy in minutes. Deploy it to a device you can’t reach and you need physical access or a complex remote rollback. You don’t need entirely new skills for edge ML. You need to be much more careful about the fundamentals you already know.
Isabella Gottardi (Arm): From Edge to Everywhere: Arm Machine Learning Inference Advisor's journey from NPU to GPU and beyond.
Isabella from Arm focused on the hardware layer with a live demo of MLIA.
When Arm first became involved in machine learning, the assumption was cloud-centric: send an image to the cloud, run inference, return the result. Today, inference runs in lots of places. Cloud platforms. IoT devices. Phones. Automotive systems. Dedicated accelerators. The same model can technically run across all of them. Performance varies wildly.
“Portability of models does not mean portability of performance.”
That’s where MLIA, the Machine Learning Inference Advisor, comes in. A way of checking compatibility and performance before you’ve committed to architectural decisions that are expensive to reverse.

The usual flow is familiar: gather data, train, optimise, deploy. Performance issues tend to show up late, when changing course is painful. MLIA shifts that discovery earlier, while trade-offs are still cheap.
Isabella showed this live. Pick a target environment. Check whether the model will run. Look at how it behaves. Try a variant. Compare the results. The tool gives you information before you’ve committed to an approach that won’t work.
With Arm’s recently announced neurotechnology, that problem only gets more interesting. Models will behave differently on different GPUs, and especially on specialised edge device hardware. The future is heterogeneous systems, where performance depends on memory layout, data movement, and how work is split across processors.
The takeaway: inference performance isn’t something you discover at the end. It’s a design input.
Sources:
Pypi package:
Rounding up
What we’re taking away from MLOps.WTF #7:
Edge forces immediate answers to questions you could defer in the cloud. Energy use, model size, and bandwidth constraints aren’t problems for later. They’re design constraints from day one.
Operational maturity matters more than hardware capability. The limiting factor isn’t compute power. It’s whether you can observe, update, and recover when systems are in the field.
Be selective about what moves. Not everything belongs at the edge. Move what benefits from immediacy and local processing. Keep what needs global context or doesn’t gain from faster turnaround.
Design for hardware reality early. The same model performs differently across different chips. Check compatibility and performance before committing, while changing course is still cheap.
As Raj put it, edge is something you arrive at when your infrastructure can support it.
About Fuzzy Labs
We’re Fuzzy Labs. Manchester-rooted open-source MLOps consultancy, founded in 2019. Helping organisations build and productionise AI systems they genuinely own.
We’re also hiring.
Open Roles
Liked this? Forward it to someone wrestling with edge deployments.
Not subscribed yet? Button link below. Couldn’t be easier.
Great posts guys I took inspiration from one of them and turned my vision into implementation
Can’t share it in public but still like to thank you guys for the knowledge you shade
Rhiannon, this captures the edge deployment reality perfectly. Raj's line -- 'edge is something you arrive at when your infrastructure can support it' -- should be tattooed on every product roadmap that casually lists 'edge deployment' as a feature.
I work in IoT connectivity and edge AI, and the operational maturity point resonates the most. We see teams that can build impressive models but have no answer for: how do you push a model update to 500 devices in the field without bricking them? How do you roll back when the new model performs worse on a specific site's conditions? How do you even know it's performing worse when your observability pipeline depends on the same constrained bandwidth the model is competing with?
Fotenix's greenhouse example is a perfect illustration of a pattern we see across industrial edge deployments. The bandwidth constraint isn't just about cost -- in many industrial environments (factory floors, agricultural sites, remote infrastructure), connectivity is intermittent or shared with operational traffic that can't be interrupted. We've deployed IoT solutions where the cellular backhaul drops to 3G during peak hours, and your model telemetry has to compete with machine control signals for bandwidth.
Sam's point about deploying the wrong model to unreachable devices hits home. In industrial IoT, the 'unreachable device' problem scales fast. When you have edge inference running on gateways across 200 customer sites with different network configurations, carrier environments, and physical access constraints, your OTA update infrastructure becomes as important as your model architecture. eSIM and carrier-agnostic connectivity help here -- you can't afford to be locked to one carrier when your devices are deployed across geographies with different coverage profiles.
Isabella's observation that 'portability of models does not mean portability of performance' extends beyond hardware to the full operational context. The same model running on the same chip performs differently when the factory is humid, when ambient temperature shifts thermal throttling thresholds, or when RF interference from nearby equipment degrades sensor input quality. Edge MLOps has to account for environmental variance that cloud deployments never face.
The one dimension I'd add to your takeaways: connectivity architecture deserves the same design-time attention as model architecture. Deciding how your edge device communicates -- cellular vs WiFi vs LoRa, which protocol stack, what QoS for model updates vs telemetry vs alerts -- shapes everything downstream. Get it wrong early and you're rebuilding your fleet management stack six months in.