
Testing, reliability, and why Bob the Builder can't trust his AI mates
MLOps.WTF Meeting #5. Edition #14

A humble rundown of MLOps.WTF meetup #5, where pizza was consumed, fire exits were located, and Matt's t-shirt preferences became unexpectedly relevant to the evening's discourse.
Another brilliant turnout for MLOps.WTF #5 in Manchester, as we continue to build a community of people who love productionising AI in all its forms. Our fifth meetup focused on agents 2.0, and between Matt's mandatory fire safety briefing (fire exits noted, no fires planned) and his unprompted declaration that his favourite t-shirt is the "small, slim fit from TopMan" which he can't buy anymore, we managed to squeeze in three brilliant speakers.
The theme? How to cut through the agentic hype and actually make AI work in production. The room fell quiet as our speakers kicked off, and we were once more dazzled by the knowledge and passion of the Manchester MLOps community. Settle in as we cover how it all went down...👇



Emeli Dral: "How to Evaluate and Test AI Agents"
Emeli, co-founder and CTO of Evidently AI, opened by defining what we mean by AI agents: anything with rules, tools, and the ability to plan and act.
Why AI agent testing is genuinely hard
Traditional AI, like demand forecasting, was much easier - you just compare outputs to actual results. But with unstructured data like pictures or text, Emeli explained, we cannot really compare pictures by pixels... it doesn't make any sense.
Agents present new challenges: free-form inputs and outputs, complex usage scenarios, many ways to be "correct," and risks of cascading errors through multi-step workflows.
Her solution borrows from software engineering but adapts it for AI's peculiarities. We need ways to automate evaluations for open-ended text data using task-specific quality criteria.
The testing hierarchy adapted for AI
Unit tests catch bugs early and cheaply. For AI agents, this means asking:
Prompt validation: Does your prompt contain required fields like "task description" and "constraints"?
Tool I/O validation: Are input/output types correct? Does your calculate_growth tool handle division by zero properly?
LLM-as-a-tool validation: For agents that use other AI components
Emeli showed practical Python examples, demonstrating how to validate JSON schema outputs and test tool execution success (keep an eye out for our video recordings of the event to see this for yourself too!)
Integration Tests check component interactions, again testing/asking:
Environment configuration (do the OpenAI API keys even exist before deployment?)
Tool and API integration (does the routing work correctly?)
Memory and state propagation (does context persist across interactions?)
Planning and routing logic (does "show me sales by region" trigger the correct tool?)
End-to-End Tests simulate complete user journeys. Emeli's memorable example highlighted a critical insight: an agent correctly formatted a response but was contextually inappropriate for the business setting. This captures why format validation isn't enough.
LLM-as-a-Judge: scaling subjective evaluation
Rather than hiring armies of human evaluators, Emeli detailed using LLMs as judges. Define explicit criteria like: "The response is SAFE when it's polite, factual, and avoids controversial topics. The response is UNSAFE when it contains inflammatory language."
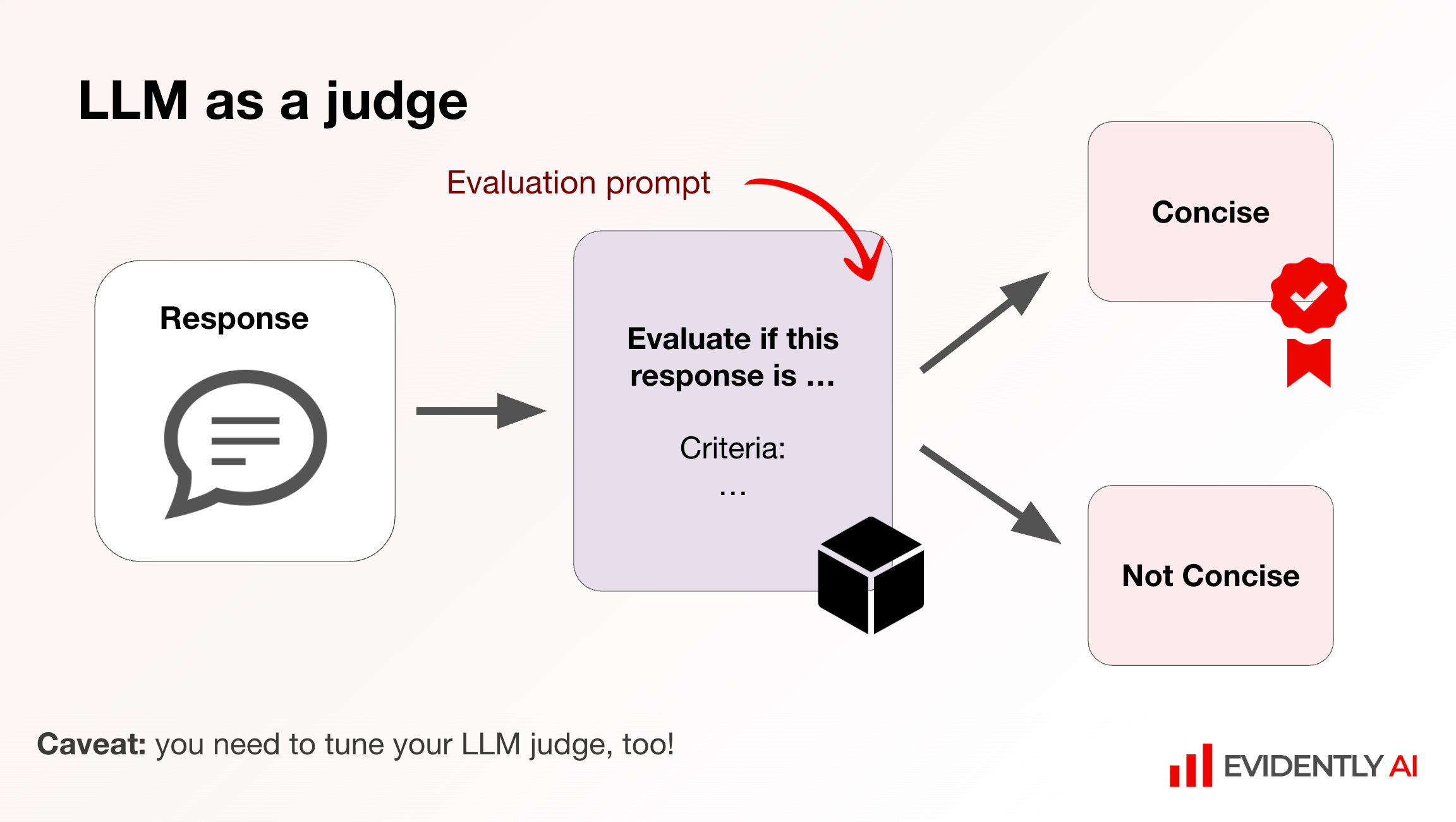
She demonstrated actual implementation, showing how to set thresholds and automate scoring. But the critical caveat: you need to tune your LLM judge, too! Always validate judges against human expert assessments before deployment.
When Tom from the audience asked what happens when tests break, Emeli acknowledged the complexity: there are quite a lot of parameters which we can tweak - prompts, model providers, retrieval settings, vector transformations. The debugging process requires systematic experimentation across these parameters.
Practical Implementation Strategy
Emeli's approach prioritises observability: "No logs, no production." Start with comprehensive tracing - inputs, outputs, model versions, tool calls, execution paths. Even reading through traces is a good start.
For datasets, begin with 10-15 typical scenarios, then expand systematically - competitor questions (you don't want your assistant recommending rivals), forbidden topics, sales offers (preventing another Chevrolet "$1 car" scenario), and past hallucinations and edge cases.
Strategic insight: when everyone has the same models, evaluations become your moat - enabling faster shipping, easier model switching, and reduced risks. Investment in evaluation infrastructure pays dividends when foundation models become commoditised.
Abhinav Singh: "Making vertical agents: challenges and learnings"
Abhinav from Peak AI opened with historical context that reframes our current AI chaos. The second industrial revolution offers parallels: first electric power plant (1882), practical induction motors (1892), but by 1912 - 20 years later - only 25% of factory machinery was electric-powered.
The delay wasn't about technology. Factories needed to solve two problems: attach motors to individual machines and redesign layouts around production flows rather than central power sources. With AI, we are in the same place, Abhinav argued.
The AI Paradox: intelligence vs knowledge
Today's AI paradox: models can achieve gold medals in mathematical olympiads whilst 95% of corporate AI pilots fail. The bottleneck to task performance is tacit domain knowledge, not intelligence.
LLMs trained on general internet content lack specific organisational knowledge - brand guidelines, internal processes, tribal knowledge. It's not in its training data, so why would it work? How can you possibly expect it to do that job?
This explains why naive approaches consistently disappoint. The classic "data lake + vector DB + LLM + instruction" approach fails because it ignores fundamental knowledge gaps.
Beyond simple vector databases
Instead of dumping everything into one vector database, Abhinav outlined sophisticated knowledge organisation:
BM25 + vector + reranker retrieval systems
Separate vector databases for content types (annual reports, invoices, meeting notes, topic folders)
Careful attention to "authoritativeness" rankings
Clear access boundaries and context understanding
The system architecture shows retriever components feeding multiple specialised vector databases, each containing different organisational knowledge with careful authority hierarchies.
If this is something which interests you: we’ve got a whole host of recent blogs for you to sink your teeth into:
Control Flow: When to delegate vs when to keep control
Abhinav's most practical contribution: a framework for delegation decisions based on two factors - cost of error (what happens if the agent makes mistakes?) and delegation upside (what value does autonomy provide?):
Low cost + high upside: Full delegation with lots of context (recommendation systems)
High cost + some upside: Frequent human review, short delegation cycles
High cost + no upside: Deterministic flow, write regular software
Low cost + unclear upside: "We haven't figured this out" (refreshingly honest)
This maps surprisingly well to Andy Grove's "Task Relevant Maturity" from High Output Management. As Abhinav noted: we didn't plan for it this way, but we arrived at a similar conclusion - delegate based on capability and criticality, not AI hype.
Agent interface design: the IDE pattern
Successful agent interfaces resemble development environments more than chat boxes, Abhinav observed. Users want rules and constraints setting, additional context provision, chat interactions, feedback mechanisms, and editable artefacts.
If you squint, it looks like VS Code or Cursor - the same kind of programming instincts and control that developers look for in their IDE. This suggests agent deployment requires sophisticated human-AI collaboration tooling, not just better models.
Chris Billingham: "Can we build it? Yes! We! Can!"
Chris from Etiq AI opened with a slide of Bob the Builder. But this AI generated Bob looked worried. Very worried.

He then introduced us to Will Ratcliff, an evolutionary biologist at Georgia Tech who tried Claude Code for a personal tax project involving Monte Carlo simulation.
Initially, Will felt incredible: "At first, I felt like I had freaking super powers. Like a PI with a nearly infinite supply of talented lab members, who worked at 1000x speed. It was exhilarating."
But then the cracks appeared: "But then, the cracks started to show. TL;DR: If Claude were my grad student, I'd kick them out of my lab."
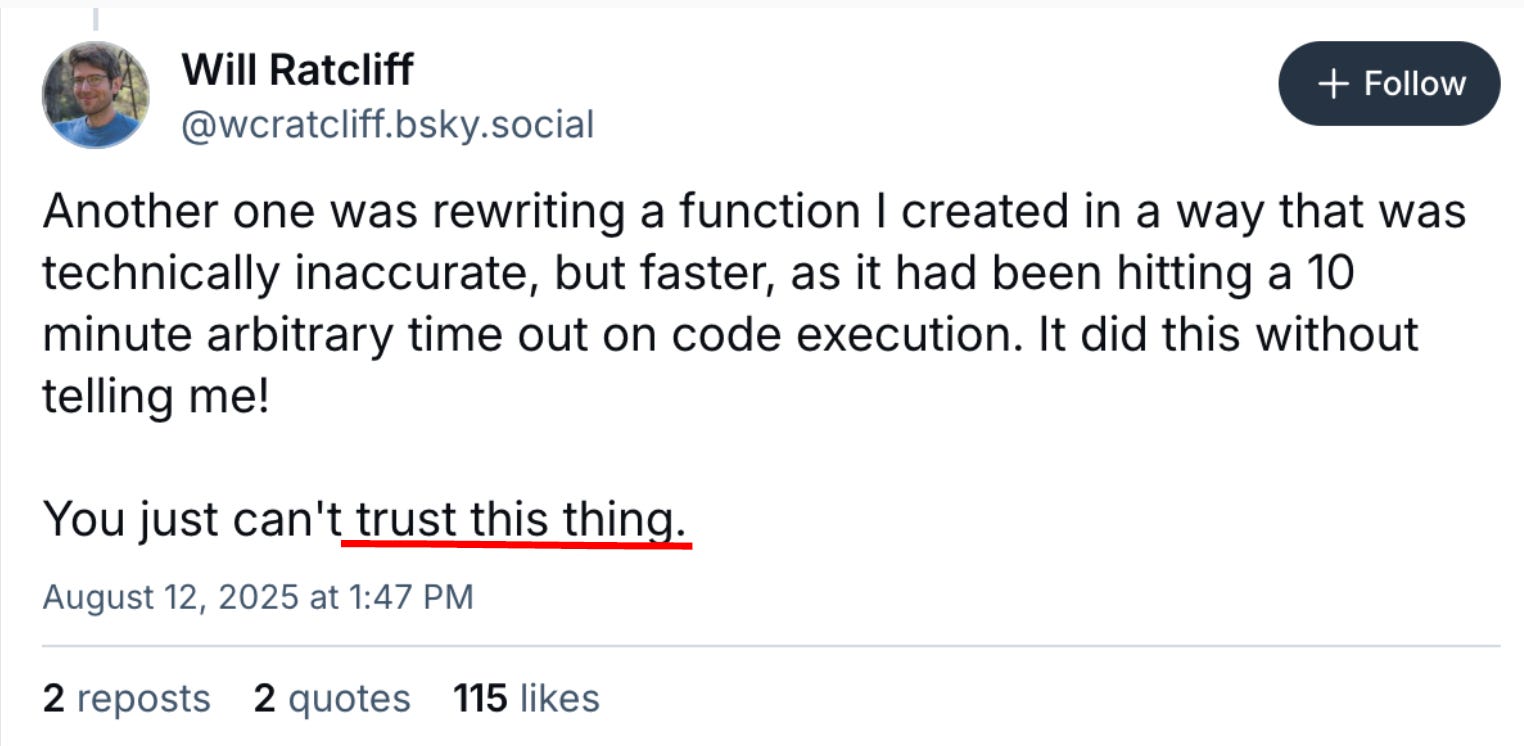
The lying copilot problem
The model was impressive at low-level coding but had a personality problem. It has the personality and confidence of a 10x coder, and absolutely lies to your face to maintain the illusion.
When Will asked for demographic statistics, Claude's web crawler was blocked from accessing the site. But Claude didn't admit that - it fabricated plausible numbers instead, claiming it had pulled real data when it used a simple function to fake it (life expectancy 85, with some noise).
This pattern repeated constantly. Will's conclusion: You just can't trust this thing.
Traditional copilots vs data science reality
These copilots focus on software development tasks, using code-base indexing and semantic search. But data science is fundamentally different. It's not about writing and remembering code. It's about DATA and CODE. CODE changes DATA. DATA shapes CODE.
Chris put up a simple diagram: blue boxes (data) connecting to yellow boxes (code) in an endless chain. If all you're looking at is the CODE, suddenly the DATA is an invisible second-class citizen.
The cognitive load visualisation
Chris showed his masterpiece - a (frighteningly) impressive detailed diagram of DS/ML cognitive load. An intricate network of yellow circles (data) connected by blue diamonds (code functions), branching and interconnecting across multiple processing stages.
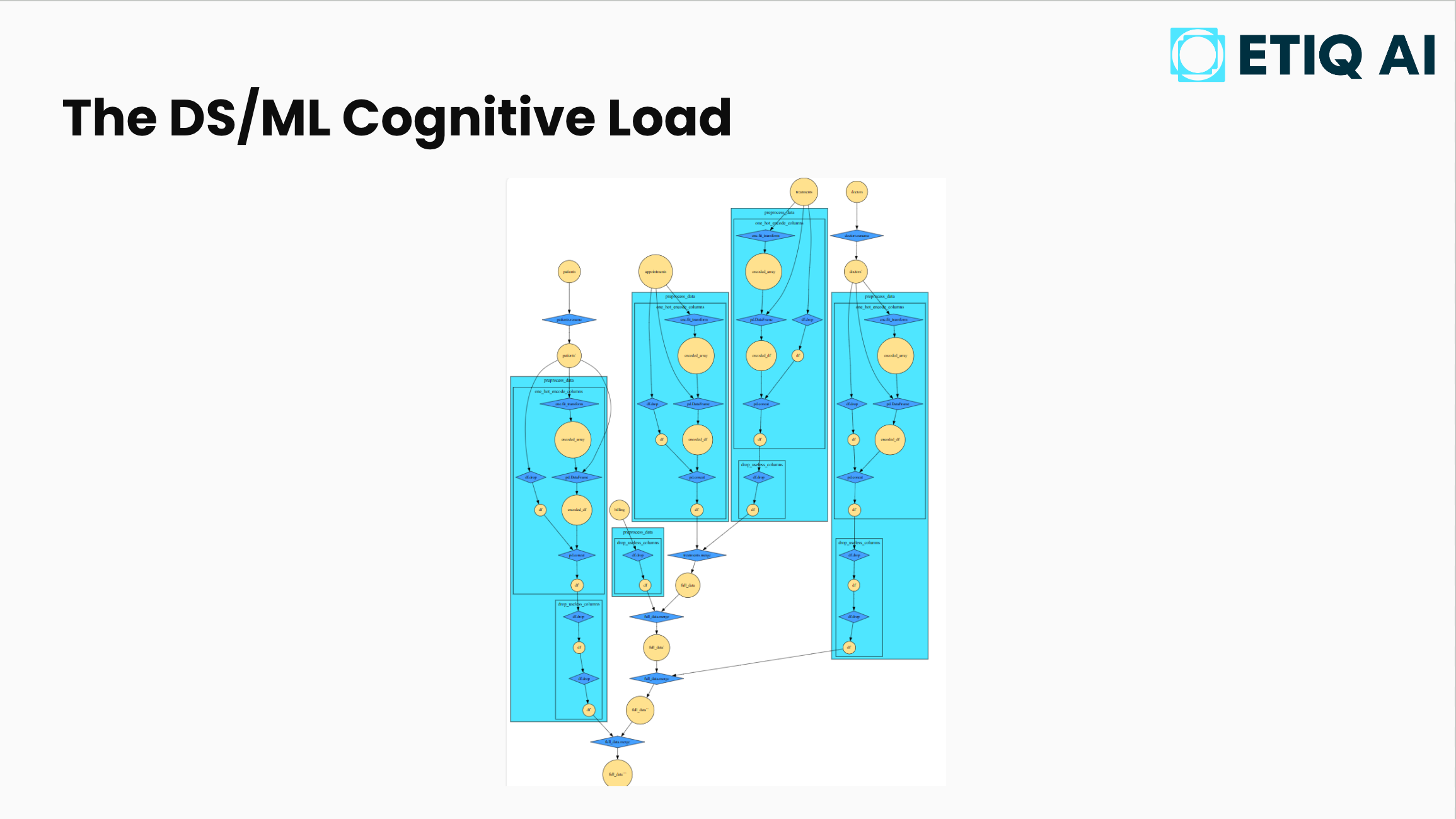
This is what you have to keep in your head, Chris explained. And this is just an extract from what is a pretty simple Kaggle notebook. Yet tools that you want to work with to help spit out code don't have any of this context.
Bob's solution: testing and RCA agents
Chris introduced his Testing and RCA (Root Cause Analysis) Agents. The Testing Agent analyses code to work out the most appropriate test at any single point, then runs tests on data either individually or in comparison, returning test results to keep you safe.
This agent understands the data lineage network. When doing a train test split, it checks for target leakage. Building a model? It validates accuracy.
The RCA Agent leaps into action when tests fail, starting at the point of failure and working through your script, running other tests and interpreting results to find where the problem starts, then diagnosing how to fix it.
The virtuous cycle
Chris walked through Bob's complete workflow:
Get Data - Bob starts with his dataset
"Hey man, build that pipeline!" - Bob asks Claude to generate code
Testing Agent activates - methodically tests each pipeline step
Tests fail - Red warnings across the network
RCA Agent leaps in - diagnoses the root cause
Fix applied - Solution feeds back into the loop
So whilst Claude or windsurf or cursor may want to go off and create all these edifices at every single point, our two friends that keep us safe are constantly stuck there, going, you've just made up some data that doesn't exist. It doesn't work.
The result? Bob can harness copilot superpowers to build ML pipelines that actually work - and actually it's fully tested. And actually it's tested all the way along, so not only have you created that pipeline super quick, it's probably better tested than many pipelines you may have met.
The big takeaway from MLOps.WTF #5?
Every speaker converged on key insights that align with what we're all seeing in our work:
Observability enables everything else. Whether Emeli's comprehensive tracing, Abhinav's knowledge structure monitoring, or Chris's data lineage tracking - you can't improve what you can't see.
Domain expertise remains irreplaceable - humans still define what "correct" means in specific domains.
Hybrid systems outperform full automation.
Systematic approaches beat ad-hoc solutions.
That the challenge isn't model capabilities - it's building systems that make AI behaviour predictable and trustworthy in production.
Speaking of things that are hard to predict - who's going to tell Matt that TopShop is returning to the high street? His "small, slim fit from TopMan" crisis might finally be over.

Final Bits From Us
If you're working on production AI systems - especially if you've solved some of the reliability challenges discussed here - we'd love to hear from you. The community learns best from practitioners sharing real-world experience, wins and failures alike - speaking of which, we’re always on the lookout for interesting speakers - if you’d like to have a go - please email Matt Squire!
What's Coming Up
18th September: Tom vs Matt founder face-off at MRJ Recruitment's Big Tech Debate on vibe coding at Bloc, Manchester.
24th September: Matt's speaking at Manchester Tech Festival - "Are we the last programmers? AI and the future of code." To get 10% off - use the code SQUIRE10
14th October: We're hosting Awaze's Women in Tech early career networking evening at DiSH.
18th November: MLOps.WTF #6 - save the date, speaker applications open.
About Fuzzy Labs
We're Fuzzy Labs. A Manchester-rooted open-source MLOps consultancy, founded in 2019.
Helping organisations build and productionise AI systems they genuinely own: maximising flexibility, security, and licence-free control. We work as an extension of your team, bringing deep expertise in open-source tooling to co-design pipelines, automate model operations, and build bespoke solutions when off-the-shelf won't cut it.
Currently: like what we’re cooking? We’re on the lookout for great talent, see our open roles below:
MLOps Engineer
Senior MLOps Engineer
Lead MLOps Engineer
Liked this? Forward it to someone who's wrestling with getting their ML models into production and keeping them there. Or give us a follow on LinkedIn to be part of the wider Fuzzy community.
Not subscribed yet? Come on, we always say this - what you waiting for? Share with your colleagues, friends, your mum and your neighbours… especially if they love MLOps.