
Monitoring, evaluating, and why you really gotta catch ‘em all!
MLOps.WTF Edition #20

Our MLOps.WTF meetup #6, where Pokémon references outnumbered technical diagrams, and the clicker staged a full rebellion pre-kick off.
It might have been cold November rain outside, but it was another record turnout for MLOps.WTF #6, our first time taking the meetup on the road to Matillion’s brilliantly retro office, complete with a green Terrazzo reception desk. The theme of the meetup, however, was anything but retro: How do you monitor and evaluate AI? And a kick off show of hands revealed about half the room knew what this meant.
When we talk about evaluations in MLOps and AI, we’re talking about the tools and techniques that give us confidence our machine learning system is working. System, not model, because the model is only a small part of it. When you’re building an AI-powered product, you need to evaluate the whole thing.
There’s also a distinction between evaluation and monitoring: monitoring is the ongoing thing you do in production because data changes and there are things you didn’t anticipate, while evaluation is what you run before deployment to understand whether the thing works correctly in the first place.
Settle in for three talks on fraud detection, interview intelligence, and digital data engineers - one with Pokémon scattered throughout, one apologising for the lack of Pokémon, and one warning us about “the world’s worst diagram.”









Daisy Doyle: “Fraud – Gotta Catch ‘Em All”
Daisy, data scientist at Awaze, committed to the Pokémon theme. Trainers and Pokéballs throughout, plus two fictional companies “Eevee Trading Cards” and “Snorlax Spa Breaks” for her case studies that she assures us bear no resemblance to anywhere real.

The scale of the problem
Last year, in the UK, e-commerce fraud hit over 3 million events, equalling over 1 billion pounds stolen and just under 1.5 billion prevented. Which at around 60%, is something, but not great.
The fraud comes in different flavours - promo abuse, chargebacks, account hijacking, triangulation - and which ones you’re dealing with shapes how you evaluate.
AWS Fraud Detector
Daisy uses AWS Fraud Detector, a fully managed service that takes 18 months of historical data with fraud/legitimate labels and builds a model. It’s a black box so you can’t see what’s under the hood, but orders get a fraud likelihood score between 0 and 1000.
She applied this to two very different scenarios…
Eevee Trading Cards: high volume, limited edition cards, with fraud trends changing every four to six weeks around new releases, mostly account takeover.
Snorlax Spa Breaks: slower moving, with fraud clustering around big Pokémon calendar events, mostly chargebacks and triangulation.
Why accuracy doesn’t work here
“If my model said all orders are legitimate, my accuracy would be 99.5%. Because fraud is typically under half a percent of all orders.”
Accuracy is useless when your data is that imbalanced. What actually matters is true positive rate and false positive rate, because you want to catch as many fraud events as possible whilst not stopping real customers, and some real orders do look a bit fishy.
Before deployment, begin by testing in stages: start with a sample of 100 fraud events to check the model catches them, then 50/50 split of legitimate to fraudulent, then the realistic ratio of 2% fraud against 98% legitimate to see if it can still pick out the signal when it’s more sparse.
AWS Fraud Detector also provides variable enrichment through their own databases of fraudulent emails, addresses, phone numbers. Geolocation enrichment worked particularly well for Eevee by cross-referencing billing address, IP address, and shipping address to flag orders placed in a different country to where they’re being shipped.
Training the trainers
Human reviewers are required for GDPR, but they have their own bias. Reviewers can anchor on an AI score even when the model isn’t that strong yet, so you need to build their confidence in the system.
This means running a trial period where you’re validating both the model and the reviewers. For fast-turnover goods like Eevee, you can let some orders through and wait to see what actually turns out to be fraud - you get ground truth to check the model against, and reviewers get to see how their judgment compares to outcomes. For high-cost items like Snorlax where chargebacks take up to a year, you invest more in the review process itself: more time, more information, let them speak to customers directly. Your business context determines how you build that confidence.
Retraining and thresholds
Retraining frequency depends on how fast your fraud moves. Fast-moving trends like Eevee need monthly or faster, while slower seasonal trends like Snorlax can be quarterly or around big calendar events. There’s also a limitation with Fraud Detector that it can only process one batch of predictions at a time, so you need to think about batching.

And how much fraud should you let happen? Sounds counterintuitive, but your model needs fraudulent data that’s definitely fraud to retrain on. When you stop an event in progress you never know for certain whether it actually was fraud. So there’s an argument for letting through a small percentage based on your risk appetite, just to maintain training data quality.
The takeaway from Daisy’s presentation: monitoring and evaluating is shaped by business context and data, not just technical constraints. And there is no such thing as too many Pokémon when it comes to MLOps.WTF presentations.
Bradney Smith: “Six Lessons in Evaluating Gen AI”
Bradney, AI Lead at Spotted Zebra, apologised for the lack of Pokémon, but he did give us six really great lessons on evaluating gen AI, so we’ll let it slide.
Setting the scene, and taking us on a story, Brad joined Spotted Zebra in August 2024. His first task: to build out the AI team and infrastructure, with his first project being “Skills Evaluation” (extracting evidence of soft and technical skills from interview transcripts.)
The only way to know if the AI was working was to have the occupational psychologists review the outputs. Make changes to prompts, send to the experts, wait for feedback, iterate.
Then a prospective client got interested. Really interested. Feedback went from informal and infrequent to formal and regular, sometimes multiple times a day. A year’s worth of development in a few months.
The manual review loop couldn’t keep up.
That’s when they built evaluation infrastructure.
Lesson 1: Golden examples
A golden example is a document where you define exactly what the correct output should be for a given input. For Skills Evaluation, that means: interview transcript goes in, correctly extracted evidence comes out. You create a set of these with your domain experts, and that becomes your gold standard to test against.
The shift is significant. Instead of sending every change to experts for review, you test against the examples they’ve already created. Now you can measure properly. Prompt engineering becomes quantifiable experiments instead of gut feel.
They stratified their golden examples by role level and industry. That granularity meant they could see exactly where prompts were failing - junior roles missing university experience because prompts only looked for workplace evidence, for instance.
When GPT-5 came out, they tested it on day one. Every new model, even in the same family, has quirks. Golden examples told them exactly what those quirks were so they could prompt around them instead of assuming newer means better, although in this case - GPT-5 is pretty good.

Lesson 2: Version your prompts
“Please don’t hard code your prompts. It makes things so much more difficult.”
Treat prompts like code. Use a structured file system with semantic versioning. They built their own format because they couldn’t find one they liked: YAML file with provider, parameters, system prompt, user prompt with templating. Everything needed to run the experiment again.
Keep a changelog so you can track how prompts improve over time. Keep a config file on prod so you can roll back without restarting the server.
Lesson 3: Model gateway
They kept finding engineers across the business writing the same API call logic over and over. Same boilerplate, different codebases, nobody maintaining it consistently. So they built a model gateway - one function in a commons library that everyone uses. It parses the prompt files, packages the API calls, captures latency and cost metrics, handles retry logic.
You build it once, and suddenly that’s one less thing for everyone to think about.
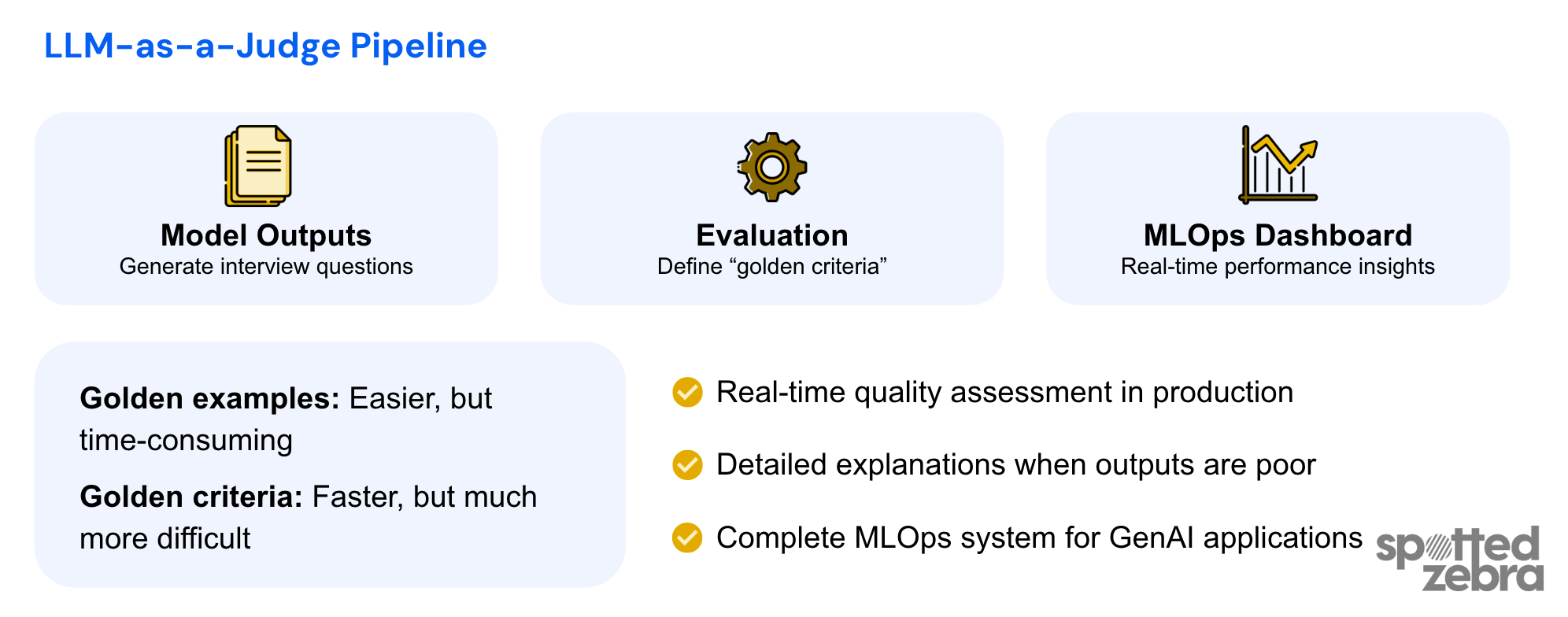
Lesson 4: LLM as a judge
Now, golden examples work when there’s a correct answer - information extraction, classification, etc. But Spotted Zebra also has a feature that generates interview questions. Suddenly there’s no single correct question - you could write thousands that are all slightly different, but all equally good.
For tasks like that, you can define your golden criteria instead. Asking what makes a good interview question? Rather than the wording of the questions themselves. The LLM judge then has your criteria and scores outputs against them. You can then use a different model family to avoid self-bias, and validate your judge against human expert assessments before you trust it.
Golden examples are for development time - you test before deployment. LLM as a judge can run at inference time, giving you continuous quality assessment in production.
Learn more about ‘LLM as a judge’ from our last MLOps.WTF meetup with Emeli from Evidently AI here.
Lesson 5: Turn failures into tests
Most teams dread production errors - Spotted Zebra used to as well, but they now maintain what they call an adversarial testing bank: a collection of the most difficult inputs they’ve encountered, e.g. edge cases, prompt injections, empty inputs, password-protected PDFs.
At scale, edge cases stop being edge cases - they become the norm. So every time they find an error in production, it goes straight into the bank.
“We used to absolutely dread seeing errors of course... but now they happen much less frequently. So when they do occur, we get a little bit excited.”
Lesson 6: Log everything properly
You don’t need logs until you do.
And you can’t predict when that will be, and when you need them you need them fast, so make them searchable.
Earning your stripes (or spots)
So what did all this get them? Development is faster because they’re not waiting for the old feedback loop. Product quality is better. When clients ask how you know your black box system is working, you can actually have an answer.
And as Bradney pointed out: the EU AI Act is coming in 2026. The companies with evaluation infrastructure will be ready.
Liam Stent: “From Vibes to Data”
Liam Stent from Matillion has been building Maia from day one. His talk: how do you go from “it feels like it’s working” to actually being able to prove it?
What is Maia?
Maia is Matillion’s digital data engineer - or rather, a team of digital data engineers. It builds pipelines, builds connectors, does root cause analysis, writes documentation. The output is DPL, Data Pipeline Language - a YAML-based format that’s human-readable.
Early reactions were brilliant - customers could see how it would change how their data engineers work. But when you’re scaling to enterprise customers paying hundreds of thousands of pounds, you need to be confident in the data. You need to be able to prove it.
Matillion has a value: innovate and demand quality, with the tagline “no product, process or person is ever finished.” They used that to drive how they measured Maia - starting simple, getting more structured, then automating.
Starting simple
They fed their certification exam to AI prompt components. Some models failed, some passed. It taught them how to use RAG effectively and get LLMs familiar with DPL using their documentation - a starting point for what “working” actually looked like.
Getting structured
They then introduced an LLM judge to measure what Maia was producing. (seeing a theme here).
This was tricky because there are many valid ways to build a pipeline - you can put everything in a Python script and get the same result as a nicely structured low-code pipeline. So they had to teach the judge what good looks like using thousands of reference pipelines.
Before trusting the judge, they validated it manually. Domain experts would write the expected answer, provide counterpoints, assess how much confidence they had in the judge’s scoring. They found judges show bias within model families, so you need to use a different model to evaluate than the one doing the work.

Automating it
They built evaluation into their test framework - runs on builds and deploys with a bank of prompts and context variations. All output goes into LangFuse dashboards: scores, time taken, tokens used, costs. Engineers drill into individual traces when something goes wrong.
“They like it when things go wrong because that’s how we’re able to learn from it.”
When Sonnet 4.5 came out on Bedrock they upgraded with confidence in 24 hours. They could show stakeholders the testing, results before and after, why they were confident. Evidence instead of gut feel.
Integrating ML skills into engineering teams
How does a traditional Java software engineering shop integrate data scientists and MLOps engineers? Don’t treat it as anything special. Same backlog, same standups, same roadmap. If the work is important, do it.
They had to educate stakeholders on why they needed engineering cycles making things better without adding features - that’s the MLOps work that makes everything else possible.
But then it just became normalised.
Good engineers want to learn from other good engineers, T-shaped skills develop naturally, and the more generalists can handle without handing over, the more experts can do deep work.
Rounding up MLOps.WTF #6
Zooming out, these are our top takeaways:
Choose metrics that actually tell you if the system is working.
Front-load expert effort into examples and criteria, not reviews.
Treat prompts like code.
Build evaluation infrastructure once.
Business context shapes every decision.
Thank you to all our speakers! You set a high bar for MLOPs.WTF, full talks will be available soon on the Fuzzy Labs youtube. (Keep an eye out!)
Final bits
Fancy your own pair of Fuzzy Labs socks? All speakers are awarded an aesthetically pleasing pair of Fuzzy Labs mathematical socks. Become our next speaker to get yours!
A final big thank you to Matillion for hosting. First time we’ve taken MLOps.WTF on the road, and we loved being at your space themed event space.
What’s coming up
Next MLOps.WTF event.
Jan 22nd. Tickets now available.
Edge AI at Arm’s fancy new office. We’re still working on the full details but one to get in the diary for the new year.
About Fuzzy Labs
We’re Fuzzy Labs. Manchester-rooted open-source MLOps consultancy, founded in 2019.
Helping organisations build and productionise AI systems they genuinely own: maximising flexibility, security, and licence-free control. We work as an extension of your team, bringing deep expertise in open-source tooling to co-design pipelines, automate model operations, and build bespoke solutions when off-the-shelf won’t cut it.
We’re hiring! Fancy becoming the next Fuzzican? Check out our careers page.
Liked this? Forward it to someone making deployment decisions based on vibes. Or follow us on LinkedIn.
Not subscribed yet? What are you waiting for?