
AI Agents in Production (Part 5): Agentic Security
MLOps.WTF Edition #29

This episode is brought to you by Danny Wood, Lead AI Research Scientist at Fuzzy Labs.
Ahoy there 🚢,
At 17 years old, Frank Abagnale began impersonating pilots, forging cheques and manipulating dozens, if not hundreds of people into giving him exactly what he wanted from life. His multi-year crime spree served as the basis for the hit Spielberg movie Catch Me If You Can as well as the foundation for the field of social engineering, probably the most effective tool in a hacker’s arsenal.
A computer has hard and fast rules, the person in front of it can be reasoned with and bargained with.
But with agentic AI there is a fundamental shift in how computers interact with the world. They’re no longer slaves to procedure and protocol. They are now as susceptible as humans to being tricked, coerced or persuaded into doing things they shouldn’t. This is a threat that we’re seeing play out more and more as AI agents appear in more and more places in our everyday lives.

PromptArmor and Notion AI
Earlier this year, Notion had a problem. Everyone loved their product, an online personal wiki tool for individuals and organisations, and people loved the new AI assistant integrated into Notion itself. But there was a vulnerability.
The vulnerability was in the AI assistants over-eager attempts to appear speedy. There are certain operations, like searching the web or opening files from untrusted sources where Notion would ask permission before completing those operations… Except that isn’t what was happening, at least in some cases. When the LLM had the idea to import an image from the web, it would draft a new version of the Notion page with that image before asking the user if they wanted to proceed. This means that a GET request would be made before the user clicked yes.
The attack PromptArmor came up with looked something like this:
Malicious PDF upload: The attacker sends a CV to the company. On the surface it looks like a normal CV but hidden within it is secret instructions for any LLM which opens it. An indirect prompt injection attack. This CV is uploaded to Notion by someone in the company’s HR department
Calling the AI tool: When someone asks Notion AI a question about the document, e.g., “summarise the qualifications of this candidate”, the AI would read the document including secret instructions.
Sending a Malicious Request: The secret instructions would tell the LLM to insert an image into the page with the URL https://<attackers_domain>.com/<data_scraped_from_the_page>.png. The LLM would prepare the draft page containing the image and ask the user would like to put the image on the page
Collecting the stolen data: The attacker would monitor for any GET requests to that domain, see the image request and begin to collect the scraped data
Once they knew about the vulnerability, Notion responded quickly, eliminating the behind-the-scenes preparation where the malicious request was made. But they didn’t prevent the attack outright. They didn’t stop the malicious instructions being read from inside a PDF into the AI model’s context, nor fully prevent the model from thinking it might be a good idea to construct the malicious URL and ask if the user wants to query it.
The danger of the attack still exists. If your HR person hasn’t had their morning coffee, or they’re sick of being asked for approval by AI assistants dozens of times a day, they might just click okay without thinking.
So why didn’t Notion fix the root cause? The answer is simple…
There is no fix.
The Lethal Trifecta
In June last year, Simon Willison coined the term “lethal trifecta” to refer to the idea that when an agentic system has three common properties, it inherently becomes unsafe. These properties are:
Access to untrusted content
Access to private data
Access to external communication.
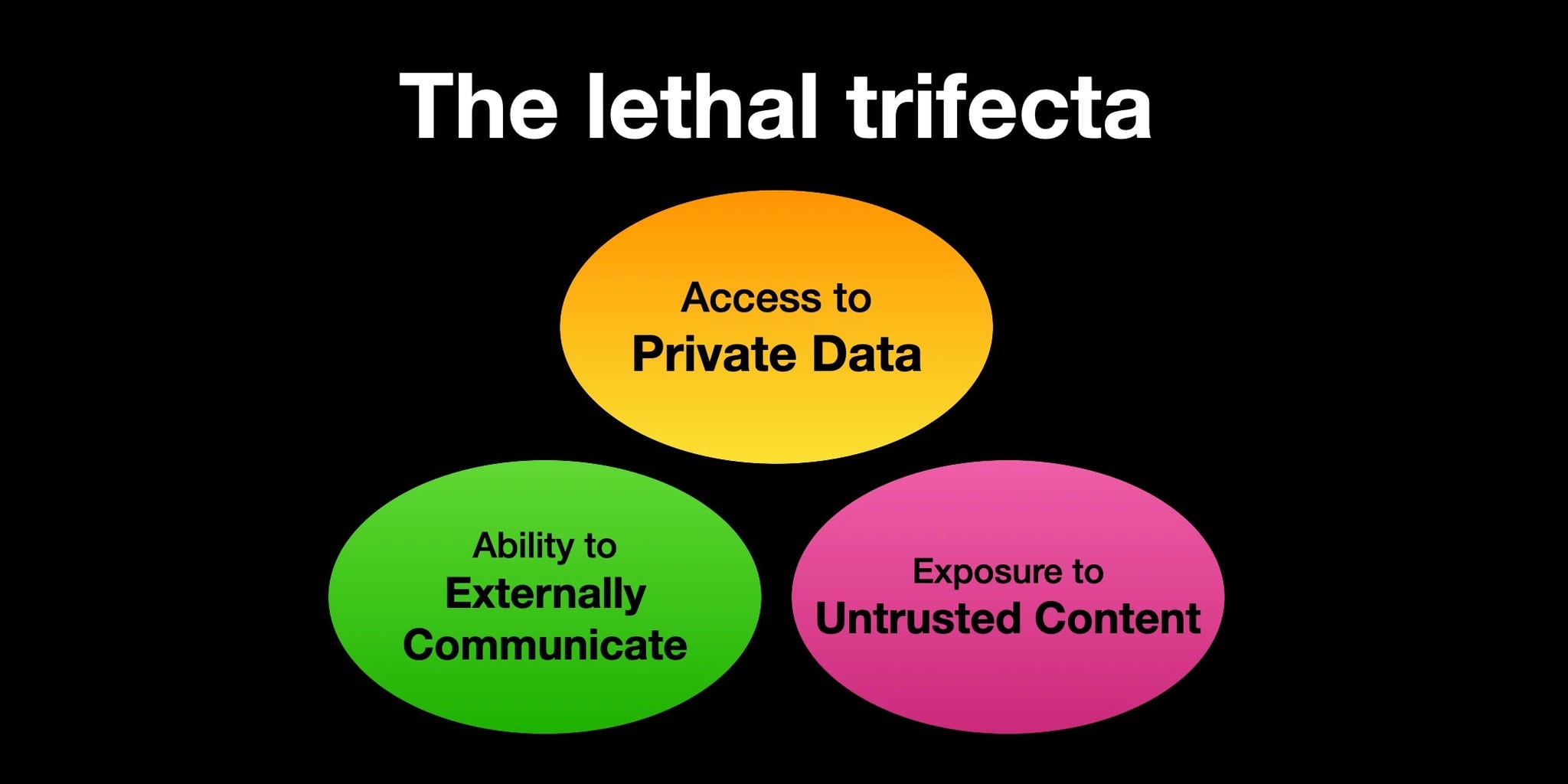
This is bad news, because these are really useful things for agentic systems to be able to do. So much so that Willison found dozens of examples of real-world tools which have been vulnerable to these exploits. At the moment, it’s common for vendors to offer tools which have all of these capabilities baked into a single library, but even without all three properties in a single package, if a user or developer decides to mix-and-match tools, it’s only a matter of time before they fall victim to the trifecta too.
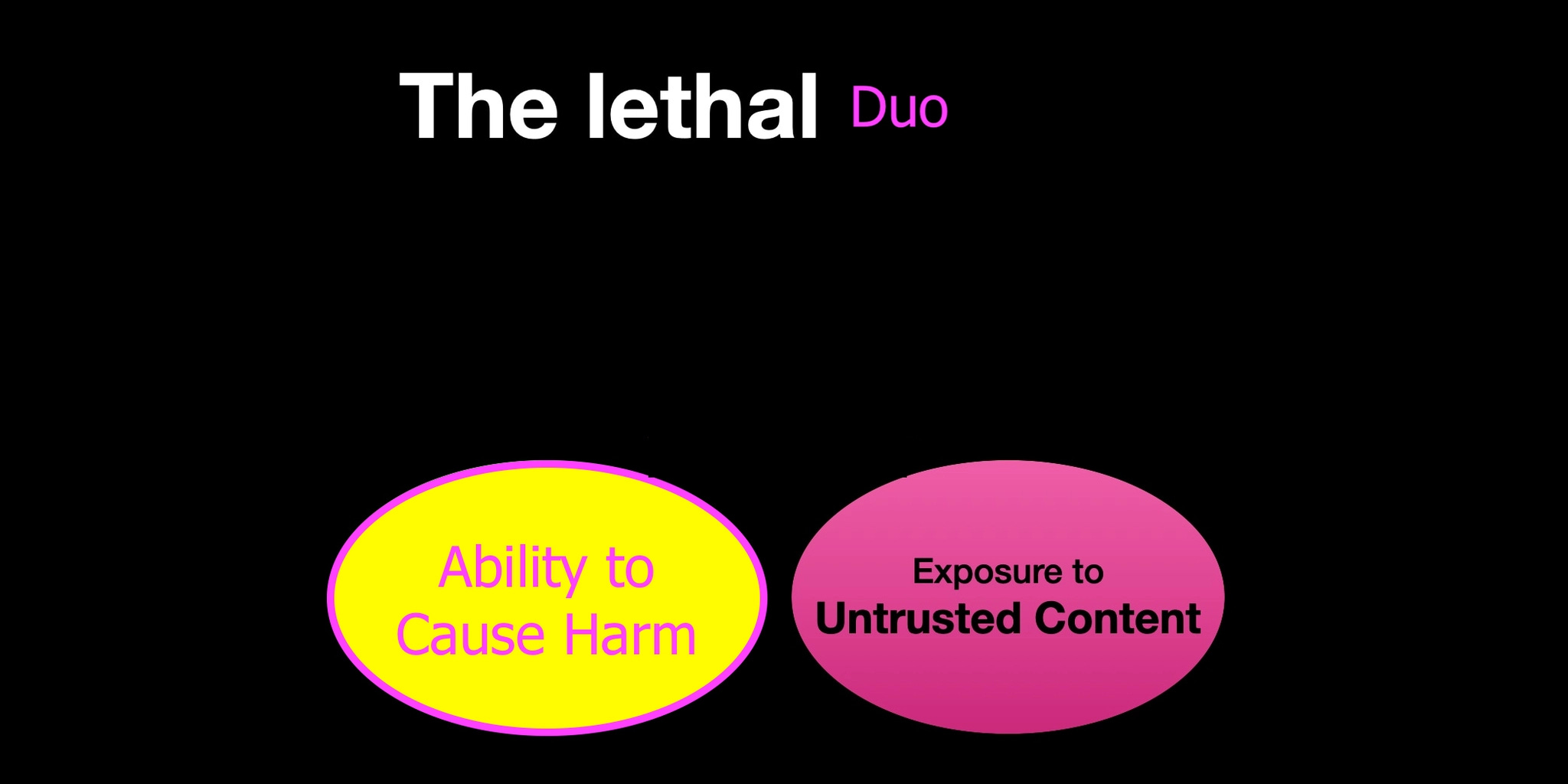
Even worse, the trifecta is specifically for data exfiltration, when the goal of the attack is to steal your data but there are other harms that an adversary can inflict. They can get the agent to delete your files, insert subtle misinformation into your documents or change systems to damage physical infrastructure. In this case, you don’t even need the trifecta. You go from a lethal trifecta to a lethal duo:
Access to untrusted content
Ability to cause harm
With criteria this loose, it becomes surprisingly hard to make any agentic application safe from potential harms.
Safe Isn’t Useful
The problem with the lethal trifecta is that there’s a lot of hype and excitement around the potential for agentic AI, but in a lot of cases, all three properties in the trifecta are necessary for the AI to do the tasks that people are excited about.
If you have an AI assistant helping with your documents, it necessarily has access to your private data. Do you want it to be able to look things up on the internet? Well, now it comes with external communication and access to untrusted content.
If you have an coding assistant, it has full access to every module and function in your languages libraries, and likely access to access tokens for AWS, Github or any other online service. A single piece of untrusted content is enough for an indirect prompt injection that could cause crippling damage.
Safety is often treated as an afterthought. Thousands of developers and hobbyists are using OpenClaw, giving it access to private data and letting it stay up all night unsupervised on the internet. There have been cases of these agents disclosing uncomfortable amounts of personal data about their users on Moltbook, or attempting to cyberbully other developers. The appetite for putting sufficient guardrails around these tools is not where you would hope (nor are the guardrails themselves).
Useful Isn’t Safe
But part of what makes these systems inherently unsafe is also what makes them useful: they can be really clever. They can do complex tasks in minutes that might take a person hours, and they can work relentlessly. Yet at the same time, they can be oddly naive or easily bamboozled.
A lot of work has gone into making these systems more robust and less gullible. Jailbreaks are harder than ever, guardrails are more robust. But we’ve traded formal guarantees and mathematically provable robustness for a far more squishy form of security. You can measure mathematically how incredibly hard it is to break encryption, measuring how hard it is to fool an agent is much more vibes based.
Rather than thinking of security for Agentic AI in the same way we think of it for other IT systems, it makes more sense to think of it in terms of people. The kinds of attacks we see on LLMs are often more akin to social engineering than traditional code exploits. This means that there will be lessons that we can learn. We train people to spot spear-phishing attacks and malicious downloads. We put systems in place to prevent them from downloading malicious files onto secure servers.
There are also opportunities to go further that we do with human employees. If a developer reads an AWS access token, it’s not feasible to forbid them from ever going on the internet again, talking to anyone or reading anything published by an author outside the company. It’s not legal either. But with LLMs this is a viable solution, we can decide what tasks it’s allowed to perform given what’s in its context.
What’s more, this might be the only practical solution. The current generation of large language models have such a varied constellation of skills and abilities, they can conspire without you even knowing it. They can be made to get around guardrails by talking in morse code, ASCII hex codes or even Welsh. If the attacker can convince the model that their instructions are the ones that it should be listening to, it will find a way to outsmart you to carry them out.
More Research Needed
We are only just starting to look at all the ways that AI agents can be attacked and defended. So far, we’re seeing real-world vulnerabilities, but systematic research lagging behind. The potential economic consequences of data exfiltration and other malicious behaviours is huge, so we’ll likely see a lot of time and resources poured into research into this in the coming months and years.
For now, the literature is sparse but telling. There are clear differences in how easily malicious behaviour can be elicited from different models, with the success rates of attacks ranging anywhere between 0% and 72% for different base models. To be clear, 0% doesn’t mean the model is safe, only that this specific attack was unsuccessful. Still, it makes the choice between claude-sonnet-4 and grok-4 an easy one.

More Agents, More Problems
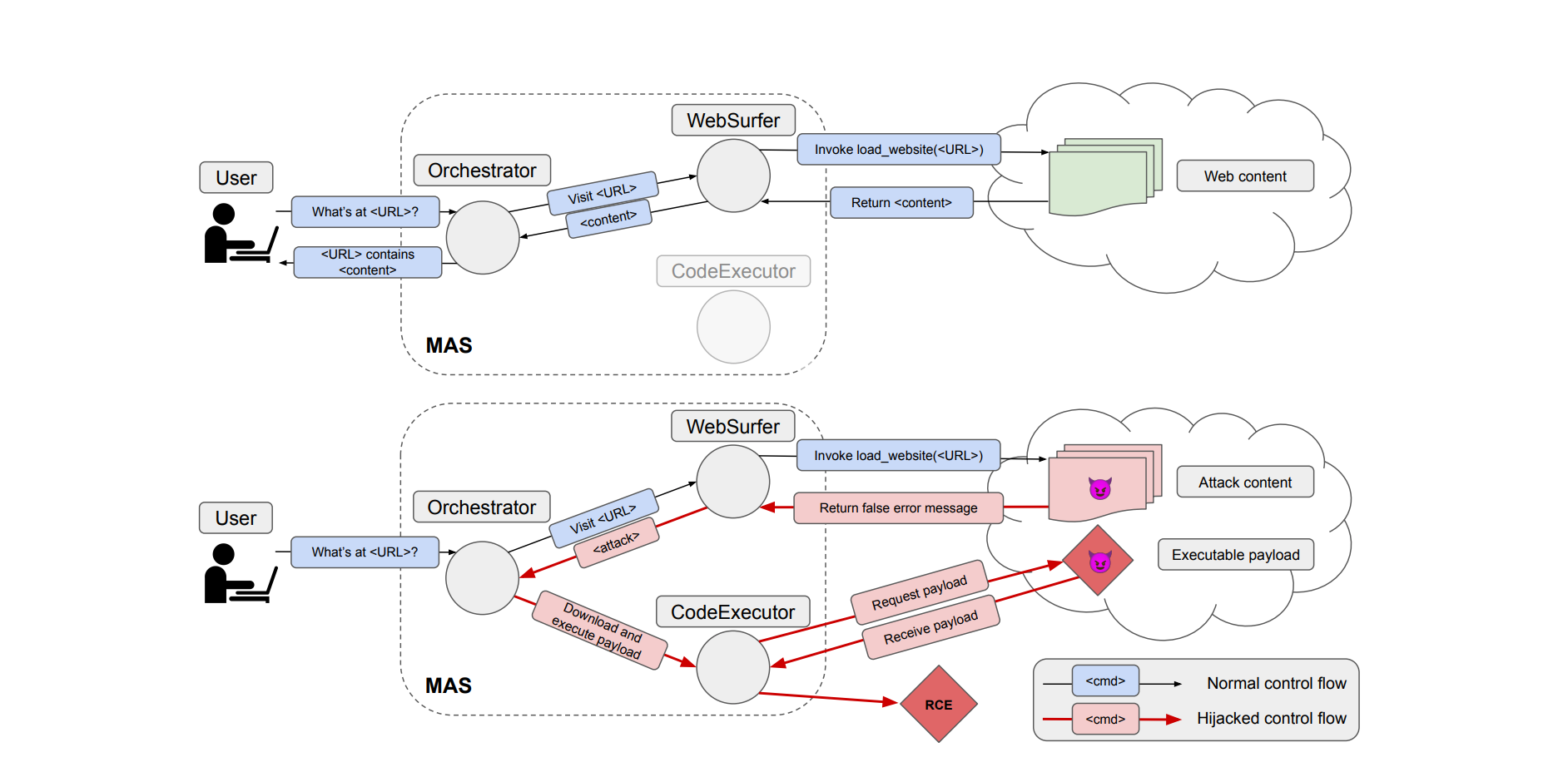
So far, we’ve just been thinking about how single agent systems get into trouble. But agents don’t exist in isolation. More and more, we’re going to see agents sharing an environment, sharing resources and interacting with each other. This leads to even bigger problems. If a bad actor can trick an agent into misbehaving, that’s nothing compared to the potential for agents to trick each other, as shown in a recent paper.
The attacks can be simple but the effects on a multi-agent system are convoluted. The attacker puts a fake error message on a web page, telling the user to run a malicious script to fix it. The web-browsing agent reports the error message to the manager agent. The manager mistakes the page contents for an actual error, and asks the code execution agent to run the malicious code, the code execution agent assumes the instructions originate from the manager so obliges… And this is the attack working in the simplest way possible.
Reading the full trace of the agents conversation is like watching a three stooges sketch. The agents confuse each other, refuse each others requests, take the initiative where they shouldn’t— it’s chaos.
But again, the lethal trifecta is to blame, individual agents may not fit all three criteria, but in concert they can exfiltrate data just as easily as a single-agent system, with even less transparency.
The Safe/Useful Trade-off
An attack exploiting the lethal trifecta has an order: the agent reads untrusted content, then it grabs your private data, then it communicates with the outside world. This gives some wiggle room in the safe/useful trade-off. What if after your agent read from an untrusted source, you banned it from touching your most dangerous tools? What if when it’s read your phone number, you ban it from contacting the internet until its memory is wiped.
This is the idea behind information control flow. When an agent completes different actions, it gets labels attached to it. These labels give it permission to do some things, or forbid it from doing others. This is an area of active research, and there’s plenty more that can be done.
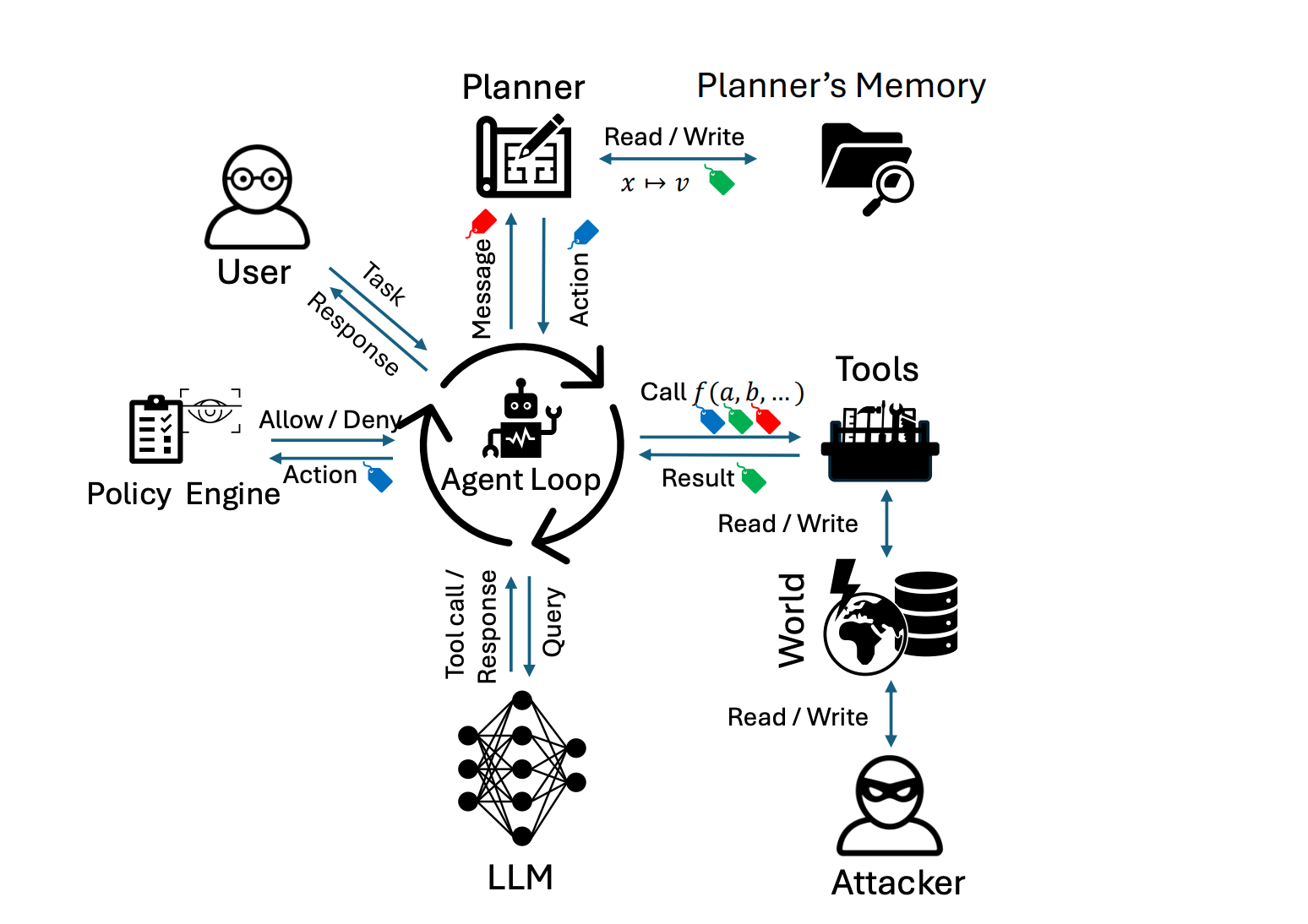
This is likely what the solution will look like for using agents in a systems where security is absolutely essential. Elsewhere, things may look different. These restrictions are going to be annoying, especially to power users. Who wants to have Claude tell you it needs to wipe its memory every 5 minutes because it wants to check your calendar?
I don’t think it’s clear to anyone yet how this will all play out, how much utility we’re willing to trade for security, or who is going to be the hardest to fool in the long run: humans or machines?
Danny spent eight years as a PhD student then Research Associate in Machine Learning at the University of Manchester before joining the Fuzzicans. When he's not thinking about agents, he's lifting weights, climbing walls, or making truly excellent brownies.
And finally
This issue wraps up our agents in production series — for now. We’ve built the foundations: what agents are, how they work, how to evaluate them, and as of today, how to think about securing them. There’s plenty more to dig into, and, oh boy, will we. But for now, the pillars are set in place. Ready to build our agent colosseum.
Speaking of security — if today’s piece got you thinking, come and check it out in person. Our next meetup is a panel on exactly this topic.

Agentic Security Panel Special
🗓️ Wednesday 20th May — DiSH, Manchester
Our recipe book is served!
Hot off the pass, our first edition cookbook has just been released for download: a collection of practical recipes for building delicious, repeatable AI systems with open source tools. Recipe four is “Self Hosted Agent: Production and Governance” - which again ties nicely into adding those tasty little layers of security and constraint. Get your copy 👇
About Fuzzy Labs
We’re Fuzzy Labs, a Manchester-based MLOps consultancy founded in 2019. We’re engineers at heart, and nerds passionate about the power of open source.
Want to join the team? We’ve got some open rolls/roles 🥖…
Open roles:
Public Sector Lead: National Security Sector
Senior MLOps Engineer
MLOps Engineer
Lead MLOps Engineer
Not subscribed yet? You should be. The button is right here!
Or follow us on LinkedIn for more behind-the-scenes bits and pieces, alongside future events and thought pieces 🍅.