
Failure is a great teacher
MLOps.WTF Edition #1

Ahoy there 🚢,
Matt Squire here, CTO and co-founder of Fuzzy Labs, and this is the first edition of MLOps.WTF, a fortnightly newsletter where I discuss topics in Machine Learning, AI, and MLOps.
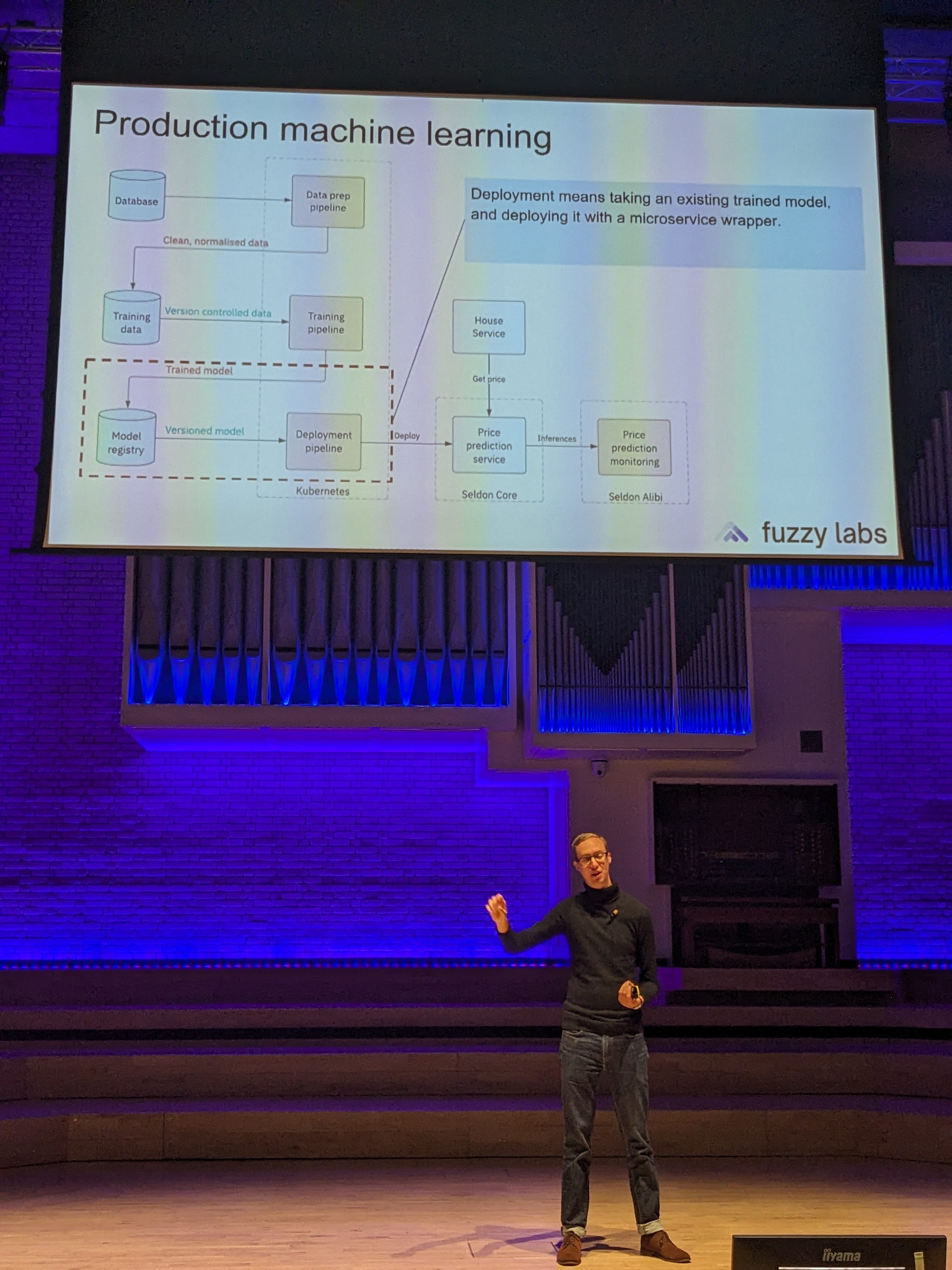
Lessons in Scaling LLMs
The first time you run an LLM it will likely fall over under the slightest load. I found this out very publically last year when, while presenting to 30-odd people, I invited the audience to try out a demo we'd been building. After the first 2 users, nothing worked, and I learned not to test the demo gods.
Scaling brings to mind at least two things: the first is minimising latency for individual users, so when a user queries a model, they get a response as quickly as possible. Second is about concurrency, supporting thousands, or even millions of simultaneous users.
As an industry, we've been here before. In the early 2000s, when hardware was expensive and the Internet was new (new for most of the world anyway), engineers tried to squeeze as many simultaneous sessions as possible out of a single server. The gold standard was the so-called C10K problem, posed by Dan Kegel: can a web server handle 10,000 connections at once?
C10K quickly became C10M (million), etc. But more importantly, it inspired a whole ecosystem of high-performance serving tools, driving popularity in technologies like Erlang and Scala, as well as the uptake of good concurrency models, from futures to actors. Moreover, it taught engineers how to think about scale, whether we expect a handful of users or millions.
It's 2024, and the circumstances that inspired C10K no longer apply. Partly, that's because our tooling is better, so developers don't need to think about the kind of optimisations faced by early web pioneers. But it's also because hardware is so cheap now that throw hardware at the problem is usually a reasonable strategy.
However, neither of those statements hold true for LLMs! In the first case, we rely heavily on GPUs for model serving, and I don't need to tell you how expensive they are; there's a reason Nvidia's share price rose ~500% in the time since ChatGPT was first announced. Plus, tools for running LLMs efficiently aren't yet where they need to be. The entire model serving stack, from API endpoints right down to model architecture and memory layout is ripe for innovation.
One example of what’s to come is vLLM. The vLLM developers have taken the idea of virtual memory (believe it or not, first invented in 1959!) as inspiration and applied that to GPU memory, resulting in the PagedAttention algorithm, which tries to optimise the key-value lookups that make up a large portion of the inference work in transformer architectures.
PagedAttention improves throughput considerably, and it makes it possible to share a GPU among multiple models too. That's incredibly valuable, because in real life you're likely to have additional models running alongside the LLM itself, like the embedding model used by a vector database, and various guardrail models, all of which can benefit from GPU acceleration.
While vLLM helps you get the most out of whatever model architecture you’re using, there’s also plenty of interest in optimising the architecture itself. So-called "small large language models" combine multiple techniques, particularly weight quantisation, to minimise memory footprint and speed up inference, something that’s been taken to an extreme with BitNet, a 1-bit LLM (the weights in BitNet are actually ternary, so this should really be called a 1-trit LLM but we won’t quibble over that).
Engineers love an optimisation challenge, and so long as Nvidia gets to set the global price of GPUs, we're going to see lots of innovation in this area. But what if the constraints change — can GPUs become either cheaper, or obsolete?
GPUs were invented for gaming. They're designed to do vast amounts of geometry calculations as quickly as possible. Coincidently, machine learning is built on exactly the same kind of mathematics as game rendering is: it's all just linear algebra. And because the industry has essentially standardised on Cuda, Nvidia's proprietary programming toolchain, it's going to be very difficult for a competitor to make an impact any time soon.
The obsolescence question is less straightforward to answer. There are real hints that novel hardware could displace GPUs for AI eventually. Tensor Processing Units, neuromorphic chips, and whatever it is the people at Extropic AI are building (not convinced I understand that one yet!) are all contenders.
AI acceleration hardware is a very deep topic, best saved for a future edition. For now, keep squeezing your GPUs.
And finally
Assorted things of interest
Spare a thought for Bartłomiej Cupiał and Maciej Wołczyk, whose reinforcement learning model for playing NetHack took a performance hit for one of the most unexpected reasons imaginable. I won’t spoil it here, go read Cupiał’s thread here.
Do you believe in straight lines? When Leopold Aschenbrenner shared his proof-by-extrapolation of imminent superintelligence, twitter was quick to dismiss him with counterexamples, from giant babies to massively scalable polygamy. My analysis predicts that by the end of this month, he will have garnered a playful response from every single person on earth.
Thanks for reading!
Matt
About Matt
Matt Squire is a programmer and tech nerd who likes AI and MLOps. Matt enjoys unusual programming languages, dabbling with hardware, and computer science esoterica. He’s the CTO and co-founder of Fuzzy Labs, an MLOps company based in the UK.
Each edition of the MLOps.WTF newsletter is a deep dive into a certain topic relating to productionising machine learning. If you’d like to suggest a topic, drop us an email!